
K8s Sera Sera

So I’ve closed off the poll in the previous post, and the clear leader with three votes is (drum roll) to have some kind of rant about kubernetes, a.k.a. k8s . So here it is.
I should probably say at the outset that I only occasionally have to use kubernetes in my day-to-day work, as we’ve now got a decent sized operations crew who handle all of this. So please don’t take any of this personally, and any disparagements below are aimed squarely at kubernetes the software and the hoops you have to jump through in order to use it.
The Kubernetes value proposition appears to be:
- get some software that works
- package it up in a docker image so that you can increase your build and deploy times by a factor of 10, and which usually ends up creating another layer of configuration around the image which is sort of like the configuration you’ve already got, but not as expressive, and arbitrarily different.
- wrap another layer of configuration around that, which is sort of like the configuration you’ve now got, but also not as expressive and arbitrarily different, but in a different way. Oh, and be prepared to have to modify that when you upgrade kubernetes.
- if you’re using helm, another layer of configuration around that layer of configuration, which is sort of like the configuration you’ve now got, but even more arbitrarily different. Oh, and be prepared to have to modify that when you upgrade helm.
- if you’re using ansible, another couple of layers of configuration on top of that, which tries to merge all your different levels of arbitrarily different configuration together, but on top of which, you’ll probably need yet another tool to manage the towering levels of complexity you’ve created by using all these tools.
- make your network and storage layers incomprehensible, and remove the ability to use swap space so your running costs go through the roof
- add more failure conditions than you really thought were possible in this day and age
I think I had a screed about PIF editors in my draft folder, let’s see if that still exists.
Well I don’t see it, so let’s rattle something off about that.
Resource allocation
OK so we’ve got this thing called an operating system, which manages these things called processes, which consume resources on your PC ( CPU, RAM, disk, network, etc ). You probably don’t give a raspberry farthing about all that, and rightly so, but if you do and you’re on Windows, then you can bring up Task Manager to show you these processes and threads that your operating system is somehow allocating time slices to every 20-60 milliseconds or so to give the illusion they’re actually running at the same time, and the resources they’re using.
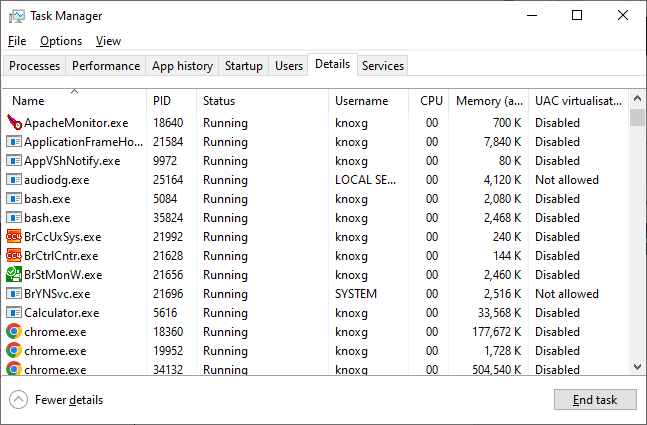
Kubernetes isn’t an operating system. Kubernetes is an attempt to move the stuff I’m pretending that the ‘Task Manager’ does onto a completely separate computer, so that it can manage those processes across other machines ( which kubernetes calls nodes, because it likes using it’s own terms for things that already have names ). Not all of the processes, the machines/hosts/nodes still do most of that, but groups of processes ( pods ) that don’t change much at all, but somehow require 3 dedicated computers to manage ( for “High Availability” ), at a speed which takes literally minutes to stop or start anything. I really cannot describe how annoying it is. I’ll try though.
PIF files
OK so for people who remember moving from DOS to Windows, you might remember these things called ‘PIF files’ ( or Program Information File files ). A PIF file was needed so that Windows could know how much memory to allocate to a process, and whether that program did anything advanced like writing to the screen without using interrupt 21, or using the printer.
We don’t have PIF files any more, and that’s because we’re not living in the 80s.
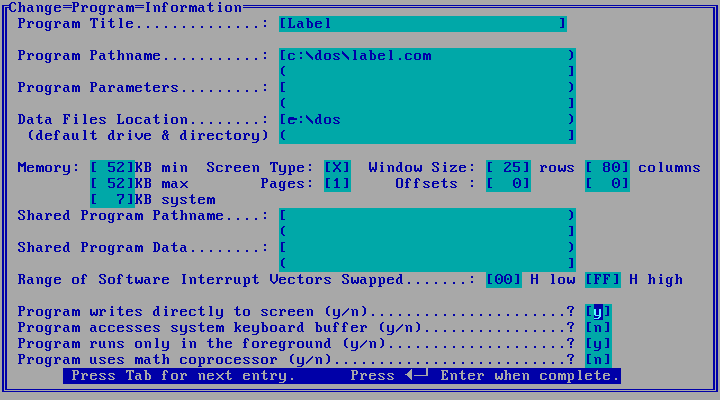 TopView PIF Editor – a text mode task switcher for 8086, probably using TSRs or something. Remember TSRs ? |
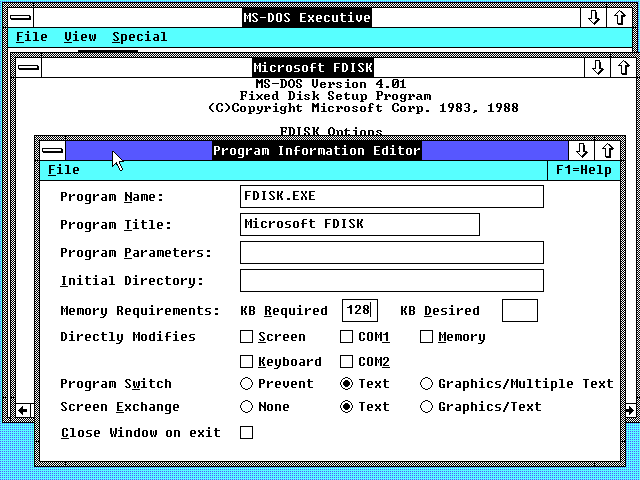 PIF Editor in Windows 2.0 – an operating system that no-one ever used |
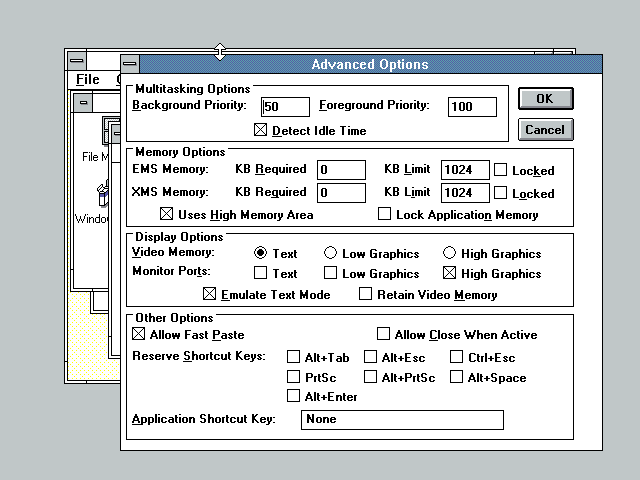 PIF Editor in Windows 3.0 – EMS memory ! XMS memory ! HMA ! |
 PIF Editor in Windows 95 – notice how many of the options don’t even exist any more. |
What we do have in 2024 though, are Kubernetes Pod configuration files, that have things like memory requests and limits ( which they could have just called minimums and maximums, but didn’t ), which are required because you need to manage memory again like you’re writing C programs. And the reason you need to manage memory is because you can’t use swap space, otherwise known as virtual memory.
Virtual insanity
Virtual memory is this thing that was created back in the 60s, which allowed your computer to run programs that it wouldn’t otherwise be able to run, by ‘swapping’ memory to disk and ‘paging’ it back again if it needed to.
Because your laptop has virtual memory, it lets you run Google Chrome with a ludicrous number of tabs open, or I don’t know Excel and Chrome at the same time, without worrying that you don’t have enough memory to run Excel and Chrome at the same time. This works reasonably well in practice because you’re usually only actually doing one or two things at a time, and you don’t need the excruciating minutiae of everything you’ve done up until now in expensive RAM.
One thing you’ll get very, very used to once you start using Kubernetes, though, are “OOM” (out of memory) errors. Because Kubernetes can’t use virtual memory , which means, if you were going to run Chrome or Excel in Kubernetes ( which you wouldn’t, because that would be both idiotic and unworkable ), you need to allocate enough memory to your chrome process to hold all your tabs, at all times, even when they’re not in use. That code that’s only used during startup ? In memory. All the time.
You’ll also get used to seeing this message many, many, many, many, many times:
0/4 nodes are available: 1 Insufficient cpu, 1 node(s) had taint
{node-role.kubernetes.io/master: }, that the pod didn't tolerate,
3 Insufficient memory.
Incentives
If you’re running this in the cloud ( and if you’re using kubernetes, you can bet you are, because getting this to run locally is yet another exercise in frustration ), memory is one of the things that your cloud provider loves to charge through the nose for.
So looking at umart ( my local nerd retailer ), you can pick up a 32GB stick of memory for around $90, which will give you the ability to use that memory in perpetuity. That works out to about $2.81 per GB, which you pay once, if you exclude the cost of the electrons to power the thing .
Google/Amazon/Microsoft will pay substantially less than $90 for a 32GB stick of memory, as they order in bulk and presumably depreciate the cost over time. If you refactor their inscrutable pricing schedule, will charge you around $92 per GB per annum for it (looking at the latest prices of t4g instances in Sydney).
Kubernetes was written by Google. Google runs a cloud provision service. I’ll just leave that there apropos of nothing.
How can we make this slower ?
Anyway, what this all means, is that a workload that you might have thought would take maybe 4 or 5 machines in the cloud ends up taking 10 or 15 machines in the cloud if you’re using Kubernetes.
Except if you were managing this yourself, you might decide to, oh I don’t know, put all the services that need to talk to each other on the same machine, but that is not the Kubernetes Way. The Kubernetes Way is to add at least two inter-machine network hops to anything that needs to talk to another service, so now you need to pay for ‘provisioned IOPS’ so that the whole mess only takes 2 or 3 times as long to run as it would if you weren’t using Kubernetes in the first place.
And because all your services are scatter-gunned across all your nodes, every time you deploy, you’ll have to wait a minute whilst an entire docker image is copied across ( which is usually equivalent to copying an entire operating system ). And if you’re rolling that out across a few nodes, those images aren’t being copied from node to node. Oh no, they’re all being sent from the one server you’re using to store your docker images on, so that becomes a bandwidth bottleneck.
And whilst this is slowly happening, with any other product you’d normally expect some kind of progress bar, which you’re not going to get with kubernetes because that kind of usability is not something they believe is worth spending time on.
Brain-dead dependency management
If you weren’t using kubernetes, you might even start your services in the right order, so that if Process B requires Process A, you might engineer things so that you actually start Process A before Process B, which isn’t the Kubernetes Way either. The Kubernetes Way is to download and install everything at the same time, and if something can’t start because it requires something else, just restart it constantly until it can. Which ends up being, you know, a lot slower than just starting the things that can start. This includes k8s system services like networking and storage classes.
Let’s start an application before I start the service that allows it to write to disk. *slow hand clap*
Inconsistent CLI
And even if you ignore the unnecessary redundant manual configuration and the decrease in runtime performance, the command-line itself is irritatingly inconsistent as well. Here’s a sample of things that annoy me:
| Command-line | Gripe |
|---|---|
kubectl get ns |
OK, so when you’re getting namespaces, it’s “ns” for namespaces |
kubectl -n some-namespace get pods |
Oh, so when you’re getting pods in a namespace, it’s “n” for namespaces |
kubectl get pods --all-namespaces |
Oh, if you’re in a namespace, the “-n” must appear before the verb, but if you want pods across all namespaces, the “–all-namespaces” must appear after the verb |
kubectl get events |
Get a list of events, in random order. |
kubectl get events --sort-by=.metadata.creationTimestamp |
Get a list of events, in the order the events were raised. This isn’t the default . |
kubectl get deployments |
OK, get a list of deployments |
kubectl scale deployment/something --replicas=0 |
scale down a deployment. What’s with the ‘deployment/’ prefix ? Why ‘–replicas’ ? |
Cattle vs Pets
So if you talk to someone in DevOps, at some point they’re going to tell you that you should treat your software like “cattle, not pets“.
I’d like to preface this bit by saying that I grew up in a fairly rural community. My father was a relatively tech-savvy cattle auctioneer who spent some of his working life in an abattoir, and at no point did we think it was a great idea to herd up the cows, and corral them down the aisles of the data centre, which is where my mind goes when I hear that phrase.
Cows are passive-aggressive lumbering bullshit-producing meat generators that are notoriously difficult to create SHA-256 hashes of, whereas pets are things that you keep around either because they provide some kind of emotional support, or alternatively to help you herd the cows into the aisles of the data centre, if that’s what you really want to do.
The “cattle not pets” crowd will tell you that you want software-as-cattle because they’re unnamed and interchangeable, and you should be orchestrating your servers so that if one fails you can replace it automatically, which is apparently what happens with cows.
Of course you don’t want some of your tech stack obliterated every time the app is upgraded, so you’ll use RDS for the database, and maybe some persistent EBS volumes to store data on.
Which is somehow an improvement on using ASG health checks to monitor and spin up new instances of servers that fall over, using RDS for the database, and maybe some persistent EBS volumes to store data on, which is what you’d be doing if you weren’t spending multiple man-years creating your exquisitely-named infrastructure-as-code YAML to configure all your interchangeable servers, which if you squint at starts to look a whole lot like the per-server configuration you used to have, doesn’t it.
I’m all for infrastructure as code by the way, but I think we could probably remove 3 or 4 layers of abstractions without much loss in functionality or reliability. And it vaguely irks me when someone who has yet to enjoy the unforgettable aroma of a cattleyard create analogies between rooms of gleaming silent servers and the fairly gruesome supply chain that makes up your Big Mac .
In summary
You know, if kubernetes was a bit more like your OS scheduler, i.e. just worked without much intervention, and just live-migrated your processes across servers as they required more resources (something that’s existed for virtual machines for a while, and which would work a whole lot easier if you could leverage the ability to swap memory to disk), then I’d be all for it.
And in fact that’s what I thought kubernetes could do before I learnt more about it. What kubernetes actually does is add a few layers of complexity and artificially constrain your software so that you’re constantly overpaying for additional resources to handle the spikes in demand you get once a week.
So sure, maybe if it was capable of live-migrating pods to a bigger server, it’d blow out your costs as it tried to reserve a terabyte of memory for some particularly badly-behaved piece of software, but I’m sure you could put in some guardrails for that. And I reckon being able to migrate processes between servers would reduce the amount of unusable-but-still-paid-for resources you currently get because your memory requests/limits don’t bin-pack into node-sized buckets evenly.
But then again, kubernetes is the closest thing to a standardised cloud deployment platform that we’ve got at the moment, so it’s a whole lot easier to hire someone who’s got kubernetes experience than to hire someone who’s got experience in whatever home-grown perl / ruby / python sellotape-and-string deployment scripts you’d use instead, so I guess there is that.
Here endeth the rant.
It’s called k8s because there’s 8 letters between the “k” and the “s”, which is something that people in IT do to words that have more than three syllables.
pods / deployments / replicasets / daemonsets / statefulsets
screenshots from ‘Running DOS Apps on Windows’ which is an interesting read in itself
well, swap memory is sort of supported in beta, but everyone seems to recommend keeping it switched off because they seem to think that predictably falling over with an OOM is more preferable to your software not falling over with a potential speed penalty
Which, from my back of the envelope calculations, comes to around $0.16p.a. ; ( 3w ÷ 32 GB) × 24 hours × 365 days = 821.95 watt hours ≈ 0.8kWh @ 20c/kWh ≈ $0.16
The only reason you might want to get a list of events is when something has fallen over and you want to see what’s happened leading up to the crash. In what universe would a user want a list of events that isn’t sorted by time ? <sarcasm>Oh, a pod just fell over ? Show me a list of everything that’s happened for the past 3 weeks in no particular order, that’ll be useful.</sarcasm>
To their credit, the LLM / “AI” crowd are definitely closing the gap on software being able to produce bullshit in industrial quantities
Getting away from cattle was a pretty major factor in why I took up a career in IT in the first place





Keep it up just browsing the internet and ran into this while needing a noun to tell my mum she is like